Deux nouvelles passées presque inaperçues ont été publiées ces derniers jours, qui devraient alimenter la réflexion de tout ceux que la “télévision augmentée” intéresse : un point sur l’état de l’art en matière de reconnaissance faciale, et une annonce de Wikipedia.
Qu’ont en commun la reconnaissance faciale et le jeu d’échecs ?

Il est frappant de remarquer que toutes les techniques d’”intelligence artificielle” (au sens large) passent un jour par le même point de singularité.
Regardons en effet du coté de la reconnaissance faciale : un article publié récemment dans medium.com fait le point sur les algorithmes les plus pointus du domaine. Il ne s’agit pas uniquement de la détection de visage (ce que la plupart des appareils photos et smartphones sont capables de faire aujourd’hui), mais de l’identification de personnes sur des photos — par exemple pour déterminer que 2 photos représentent la même personne (l’article propose d’ailleurs au lecteur un petit test).
Tout comme il y a quelques années le monde des échecs a été marqué par l’entrée dans l’ère de la suprématie de l’ordinateur sur l’être humain, celui de la face recognition est maintenant dominé également par les ordinateurs !
L’article explique en effet que l’algorithme GaussianFace développé par Chaochao Lu et Xiaoou Tang de l’Université de Hong Kong vient justement d’arriver à un taux de détection de 98,52% en moyenne (incluant les faux négatifs et les faux positifs), alors que le meilleur physionomiste humain n’arrive péniblement qu’à un taux de 97,53% ! (voir graphique ci-dessous)
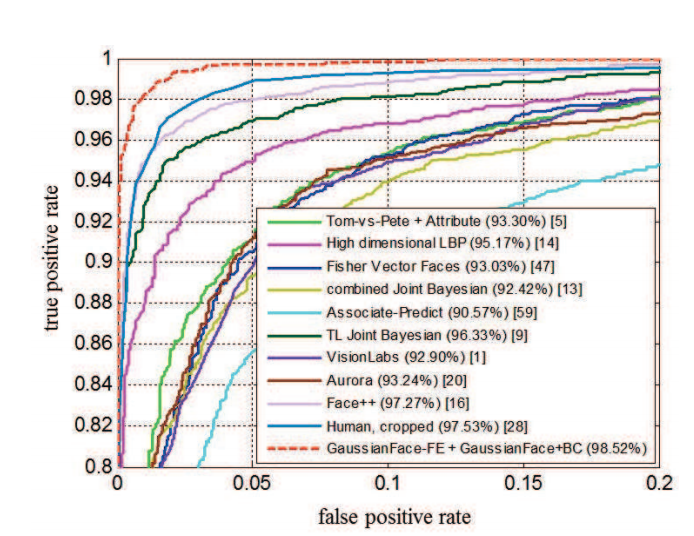
Qu’en conclure ? Que nos ordinateurs, s’ils sont convenablement entrainés, sont maintenant prêts pour reconnaitre les personnalités apparaissant dans une photo, par exemple extrait d’une vidéo — une perspective certainement inquiétante quand il s’agira de n’importe quel visage, apparu sur les images de n’importe quelle caméra. Mais c’est également une technologie qui ouvre des possibilités très intéressantes quand les personnalités sont publiques, et que le flux vidéo provient de la télévision… surtout si on combine cette approche avec du contenu enrichi !
Wikipedia: toujours plus !
Coté contenu justement, comme l’a noté Numerama, Wikipedia a passé cette semaine le cap des 1,5 millions d’articles en français. Bien sûr notre langue est loin derrière l’anglais, qui reste prééminente sur Wikipedia (4,5 millions d’articles), mais également derrière le néerlandais, l’allemand et le suédois ! (à ce propos, la lecture de la page de Wikipedia regroupant quelques statistiques utiles et inutiles est intéressante…)
Outre le coté anecdotique de savoir quelle est la un million cinq-centième page en français, une simple constatation s’impose : Wikipedia est une formidable source d’information, y compris en français ; très riche, souvent fiable, et même souvent très précise ! Il suffit de se connecter sur une page quelconque en rapport avec l’actualité pour s’apercevoir qu’une main experte y a mis très récemment à jour les informations pour coller au plus près des dernières nouvelles.
So what ?
Que conclure de tout cela, et quel est le rapport avec la télévision augmentée ? Simplement ceci : imaginez la richesse aujourd’hui à portée de main, lorsque l’on combine la puissance des algorithmes de reconnaissance de données (reconnaissance faciale, reconnaissance audio, analyse syntaxique et sémantique de texte, etc.), avec la profondeur des informations disponibles sur le net, que ce soit sur Wikipedia ou sur d’autres sources (Freebase, IMDB, AlloCiné, et beaucoup d’autres). Imaginez en particulier les possibilités d’identification, d’enrichissement, de fact checking, etc. offertes aux téléspectateurs devant sa télé…
Comme vous le savez si vous êtes déjà un lecteur assidu de ce blog, c’est bien là que réside l’ambition de TiVine Technologies, avec l’application TiVipedia : offrir à chacun, grâce aux technologies que nous mettons en œuvre, sa propre télévision augmentée !
-N.Mercouroff, Président de TiVine Technologies